

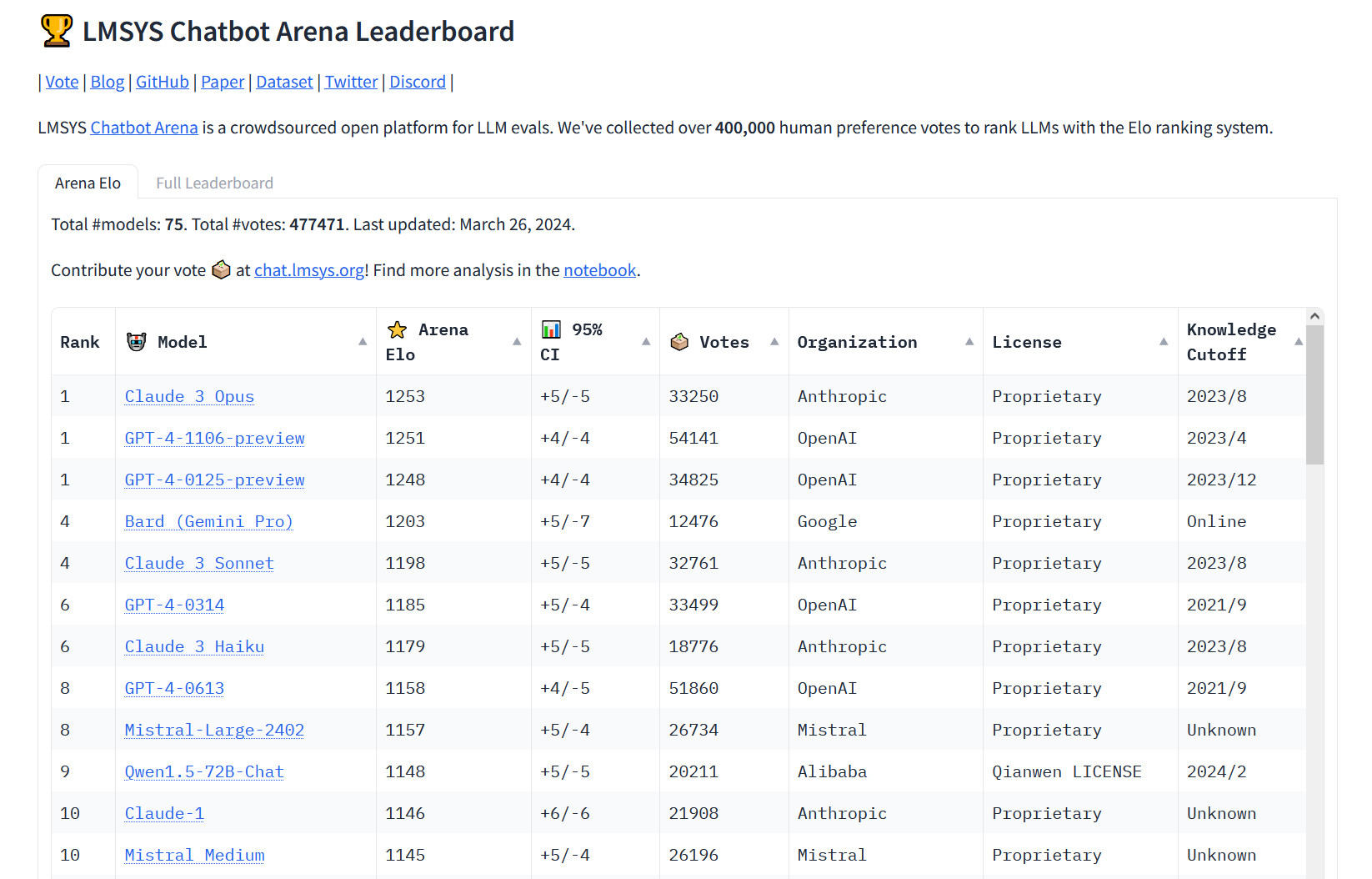
On Tuesday, the popular crowdsourcing website Chatbot Arena introduced OpenAI’s GPT-4 model (which powers ChatGPT) to Anthropic’s Claude 3 Opus Large Language Model (LLM) for the first time. Leaderboard It is used by AI researchers to measure the relative power of AI language models. “The king is dead,” chirping Software developer Nick Dobos compared GPT-4 Turbo and Claude 3 Opus in a post that was shared on social media. “Rip GPT-4.”
Since GPT-4 was included in the chatbot arena Approximate May 10, 2023 (The leaderboard has started 3. May So far this year, versions of GPT-4 have consistently topped the table, so its defeat in Arena is a significant moment in the relatively short history of AI language models. Haiku, one of Anthropic’s smaller models, turned heads with its performance on the leaderboard.
“For the first time, the best models available – Opus for advanced work, Haiku for cost and efficiency – come from a vendor other than OpenAI,” independent AI researcher Simon Willison told Ars Technica. “It’s reassuring – we all benefit from the diversity of major providers in this area. But GPT-4 is over a year old at this point, and it’s taken this year for everyone else to catch up.”
Bing Edwards
Chatbot Arena is managed Large model systems organization (LMSYS ORG), a research organization dedicated to modeling and working as a collaboration between students and faculty at the University of California, Berkeley, University of California, San Diego, and Carnegie Mellon University.
We described how the site works back in December, but in a nutshell: Chatbot Arena shows a user visiting the site a chat input field and two windows displaying the results of two unnamed MBAs. The user’s task is to evaluate which output is best based on what he considers to be the most appropriate criteria. Through thousands of these individual comparisons, Chatbot Arena calculates the overall “best” models, populates the leaderboard, and updates it over time.
The chatbot arena is important because researchers and users are often frustrated when trying to measure the effectiveness of AI-powered chatbots, whose widely varying results are difficult to measure. In fact, we wrote about how difficult it is to objectively measure a master’s degree in our news article about the Cloud 3 launch. In this story, Willison emphasizes the important role of “feelings” or subjective feelings in determining the quality of work. the master “This is another case that emotions are a key concept in modern AI,” he said.

Bing Edwards
There is often a “good vibe” in the AI space, where numerical benchmarks that measure knowledge or testing skills are often adopted by vendors to make their results seem more relevant. “I had a long programming session with Cloud 3 Opus and the man absolutely destroyed the GPT-4. I don’t think the benchmarks do justice to this model.” chirping March 19 AI software developer Anton Bacaj.
The rise of Claude may have stalled OpenAI, but as Willison points out, the GPT-4 family itself (despite being updated several times) is over a year old. Currently, Arena lists four different versions of GPT-4, which are incremental updates to LLM that get stuck over time because each has a unique output style and some developers use them with OpenAI’s API, requiring compatibility so that their applications Can be created in GPT. Output -4.
This includes GPT-4-0314 (the “native” version of GPT-4 from March 2023), GPT-4-0613 (snapshot of GPT-4 from June 13, 2023, “with improved function call support”, accordingly OpenAI), GPT-4-1106-preview (starting version of GPT-4 Turbo from November 2023) and GPT-4-0125-preview (latest model of GPT-4 Turbo, from January 2024) intended to reduce “lazy” instances ).
But despite four GPT-4 models on the leaderboard, Anthropic’s Claude 3 models have continued to climb the charts since their release earlier this month. Claude 3’s success among AI assistant users has led some LLM users to replace ChatGPT in their daily workflow, potentially reducing ChatGPT’s market share. At X, software developer Pietro Schirano book“Really the most brutal thing about Cloud 3 > GPT-4 is how easy it is to change??”
Google’s similarly powerful Gemini Advanced has also gained traction in the AI assistant space. This may spell trouble for OpenAI for now, but in the long term the company is developing new models. A major new successor to GPT-4 Turbo (called GPT-4.5 or GPT-5) is expected to be released sometime this year, possibly in the summer. It’s clear that the LLM space will be full of competition at this point, which could lead to more interesting changes in the chatbot arena rankings in the coming months and years.











{kind=link}